在本次流程说明中,我们会利用威栗camera 的手写字母识别功能,实作一个能识别英文单字的Python程序。
在手写字母识别功能里,威栗camera不仅能侦测英文字母,它也能告诉使用者各个字母的出现位置。通过以上资讯,我们可以精确地识别使用者提供的手写单字。
接下来,我们一步一步介绍如何汇入威栗camera 所需函数库、如何读取并利用威栗camera的回传数据,达成本次实作目标。
若您尚未建立Python 编程环境,请先参考“Python 环境设置流程说明(https://pixetto.ai/tw/2020/08/python-environment-setup-tw/)”。
步骤 1
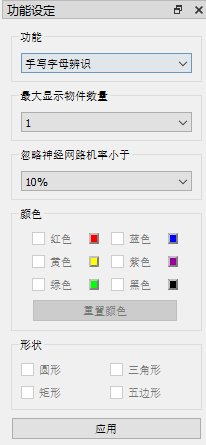
将威栗camera连接至电脑后,开启CZL智能传感器工具。在右方选单中选择“手写字母辨识”。由于我们需要同时识别多个字母,请将“最大显示物件数量” 设为5。
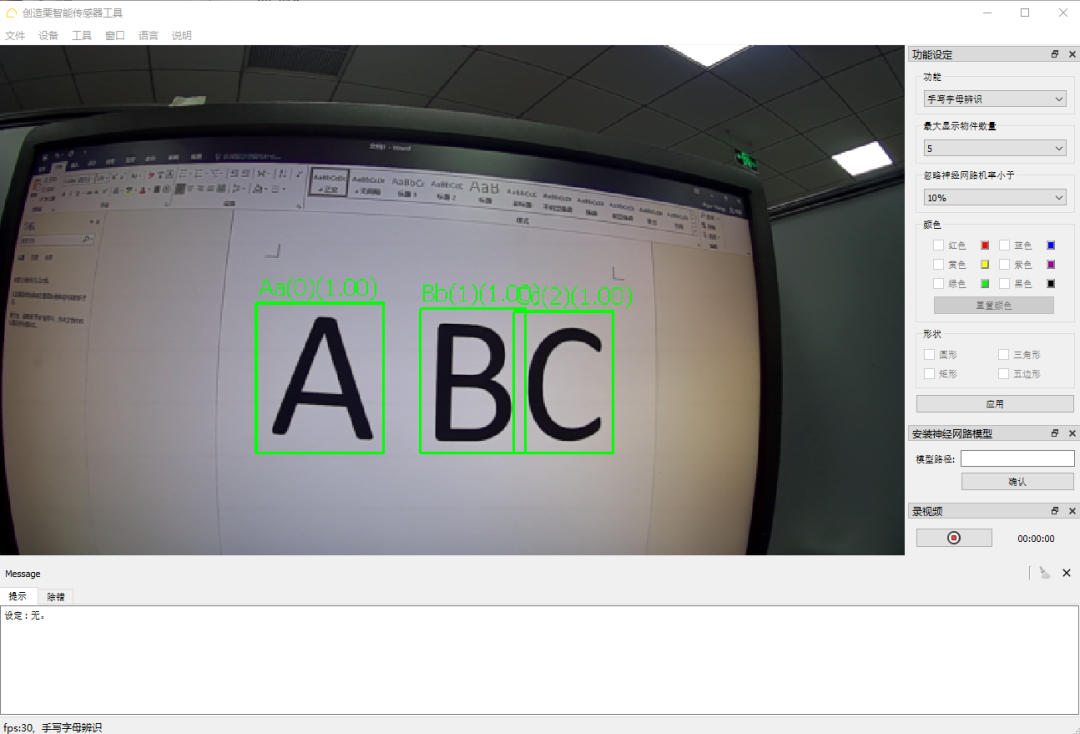
完成后,即可测试威栗camera 是否能正确识别字母。
步骤 2
开启Jupyter Notebook,并建立一份“ipynb”档案。

在第一栏code cell 里,汇入威栗camera 以及collections 等函数库。
from pixetto import Pixetto
from collections import defaultdict, Counter
在Python 程序里,我们会将威栗camera 视为一个“类别” ( Class )。在后续的步骤中,我们可以直接呼叫类别中的“方法” ( Method ),以开启、关闭、或读取威栗camera。
第二行的“defaultdict” 以及“Counter” 是处理资料时常用的工具。在之后的步骤,我们会对这两种工具进行更详尽的介绍。
步骤 3
在本次实作中,我们需要建立一个单字库,让程序认识英文单字。之后的步骤,我们会让程序在侦测到正确的英文单字后停止。
在这个步骤中,我们需要用到“Counter” 函式。“Counter” 会读取传入的阵列,并以阵列中的元素为键( Key ),各元素在阵列中出现的次数为值( Value ),转换为字典( Dictionary )。
请先到网站( https://norvig.com/big.txt ) 下载文字档至您的资料夹下。接着,让Python 读取档案,将所有文字以空格作为区隔后,存入“words” 阵列。最后利用“Counter”,将阵列“words” 转换为字典( Dictionary ) “WORDS”。
import re
text = open('big.txt').read()
words = re.findall(r'\w+', text.lower())
WORDS = Counter(words)
完成后,我们可以得到任意单字在“text” 的出现次数。
步骤 4
接下来,我们会宣告三个“defaultdict”,分别为“confidence”, “x_position”,以及“candidates”。
“defaultdict” 是一个能赋予预设值的字典(Dictionary )。宣告时,可以利用“lambda” 为每个键( Key ) 赋予预设的值( Value )。
例:若要宣告一个预设值皆为0 的“defaultdict”,可以输入以下程序码。
example_dictionary = defaultdict(lambda: 0)
本次实作中,我们需要将“confidence”, “x_position”, 以及“candidates” 三个字典( Dictionary ) 的预设值设为0。
confidence, x_position, candidates = defaultdict(lambda: 0), defaultdict(lambda: 0), defaultdict(lambda: 0)
“confidence” 总共有26 个键,分别为26 个英文字母,各自记录着它被威栗camera 侦测到的信心程度。每当威栗camera 侦测到某字母时,该字母在“confidence” 中的值便会上升。您可以将其理解为每个字母被侦测到的次数。经过多次侦测,“confidence” 中拥有最高值的几个键( Key ),即为手写单字中出现的字母。
“x_position” 记录着各个字母在影像中的X 座标。数值越小代表它位于单字的左方,越大则代表位于右方。
创建完“defaultdict” 后,宣告一个包含所有字母的字串,以便之后对各个字母进行操作。
alphabets = 'abcdefghijklmnopqrstuvwxyz'
为了让程序更容易理解,我们可以让使用者提供单字的长度。
word_len = int(input('Input the length of the word: '))
步骤 5
接下来,宣告一个威栗camera Class,并连接指定的威栗camera 视觉传感器( COM3 )。
pix = Pixetto()
pix.open("COM3")
连接威栗camera 视觉传感器后,我们可以先尝试读取威栗camera 的侦测资料。
while True:
if pix.is_detected() == True:
print(pix.get_data_list())
pix.close()
利用“get_data_list()” 读取威栗camera 回传资料。每一笔资料都由两个数字以及一个阵列所组成。第一个数字代表威栗camera 目前的功能代号( 手写字母辨识),第二个数字代表威栗camera 侦测到之字母数量。最后的阵列则是由每个侦测到的字母的详细资料所组成,除了字母( label ),亦包含了威栗camera 的辨识信心程度( confidence )、字母宽度高度( w, h ),以及XY 座标( x, y )。
步骤 6
现在我们可以接收并记录威栗camera 的回传资料。
首先以“objs” 记录回传的阵列。由于我们只需阵列中的资料,无需第一及第二个回传数字,因此可以先以底线“_” 带过。
while True:
if pix.is_detected() == True:
_, _, objs = pix.get_data_list()
for item in objs:
letter = item['label'][1] # 取小寫字母
x_pos = item['x']
conf = item['confidence']
变数“objs” 是一个记录侦测到之字母的阵列。我们可以利用“for” 回圈对阵列中每个元素做处理。
在回圈里,宣告三个变数,分别记录侦测到之字母( letter )、字母之X 座标( x_pos )、以及威栗camera 的信心程度(conf)。
在字典“confidence” 中,将侦测到的字母对应到的值( Value ) 依据信心程度加上一定比例的值。为了不让数值过高,可以使用“min” 函式,将其上限设为100。
在字典“x_position” 中,将侦测到的字母( letter ) 对应到的值( Value ) 更新。
for item in objs:
letter = item['label'][1]
x_pos = item['x']
conf = item['confidence']
confidence[letter] += 10 * conf
confidence[letter] = min(confidence[letter], 100)
x_position[letter] = x_pos
conf = item['confidence']
字典“confidence” 的资料处理完后,请在“for” 回圈外,依据“confidence”中的各个值( Value ) ,由大到小做排序,并由“result_1” 记录前“word_len”名( “word_len” 为单字字母个数)。
result_1 = sorted(confidence.items(), key=lambda item: -
item[1])[0:word_len]
“result_1” 记录了威栗camera 所侦测到的字母。但我们仍需依据各个字母的X座标进行排列。
result_1 = sorted(confidence.items(), key=lambda item: -
item[1])[0:word_len]
result_2 = []
for item in result_1:
result_2.append([item[0], x_position[item[0]]])
result_2 = sorted(result_2, key=lambda item: item[1])
为了防止误判的字母在字典“condifence” 中的值居高不下,我们可以在每次读取威栗camera 后,将所有字母的信心程度下降。
for i in alphabets:
if confidence[i] >= 2:
confidence[i] -= 2
else:
confidence[i] = 0
现在,我们可以对程序码进行测试。
步骤 7
在这个步骤中,我们要让程序在侦测到正确单字后停止。
首先,我们必须确认单字出现在单字库中,并且长度必须等于使用者在前面步骤输入的“word_len”。
若是上述条件都符合,将该单字在字典“candidates” 中的值加一。
if WORDS[word] != 0 and len(word) == word_len:
candidates[word] += 1
当侦测到的单字在字典“candidates” 中的值超过十,便暂停程序,显示该单字于萤幕上,并且询问使用者是否继续侦测。
if WORDS[word] != 0 and len(word) == word_len:
candidates[word] += 1
if candidates[word] > 10:
print('\nFinished detecting!')
print('Word detected: ', word)
correct_word = input('Continue detecting? (y/n)\n')
若是使用者输入“n”,则跳出“while” 回圈,结束程序。
若是输入“y”,则将“candidates” , “confidence”, 以及“x_position” 重制,并询问下一个欲侦测单字的长度。
correct_word = input('Continue detecting? (y/n)\n')
if correct_word == 'n':
break
elif correct_word == 'y':
word_len = int(input('Input the length of the word:'))
candidates.clear()
confidence.clear()
x_position.clear()
我们已经完成了所有的程序码了。现在,您可以在白纸上写下五个字母以下的英文单字,并试着让威栗camera 视觉传感器辨识。
结束识别后,别忘了关闭威栗camera。
pix.close()
恭喜您完成了!
